23. Release Notes¶
23.1. Robin Cloud Native Platform v5.3.13¶
The Robin Cloud Native Platform (CNP) v5.3.13 release has new features, improvements, fixed issues, and known issues.
Note
Robin CNP v5.3.13 is supported only for IPv4 environments.
Release Date: 26 August 2022
23.1.1. Infrastructure Versions¶
The following software applications are included in this CNP release.
Software Application |
Version |
|---|---|
Kubernetes |
1.21.5 |
Docker |
19.03.9 |
Prometheus |
2.16.0 |
Prometheus-adapter |
0.9.1 |
Node-exporter |
1.1.2 |
Calico |
3.12.3 |
HA-Proxy |
1.5.18 |
PostgreSQL |
9.6.24 |
Grafana |
6.5.3 |
23.1.2. Upgrade Path¶
The following is the supported upgrade path for Robin CNP v5.3.13:
Robin v5.3.11 (HF3) to Robin v5.3.13 (GA)
23.1.3. New Features¶
23.1.3.1. License Expiry Verification¶
Starting from Robin CNP v5.3.13, Robin CNP verifies the license expiry date and generates events and alerts. A warning alert is generated seven days before the license expiry date, a license expired event is generated when the license expires, and other license expiry-related events.
You can set the interval for verifying the license status using the robin schedule update command.
The license expiry verification feature is by default set to True.
Robin CNP provides the following events and alerts:
EVENT_LICENSE_NOT_ACTIVATED - This event is generated when the license is not activated after installing Robin CNP.
EVENT_LICENSE_EXPIRATION_WARNING - This alert is generated when the license is going to expire.
EVENT_LICENSE_EXPIRED - This event is generated after the license is expired.
EVENT_LICENSE_EXPIRING_TODAY - This alert is generated if the license expiry date is the same current date.
You can view the events and alerts by using the robin event list and robin alert list commands. You can also view the events and alerts from the Robin CNP UI.
23.1.3.2. Robin CNP Installation Supports Custom CA certificate and key¶
Robin CNP 5.3.13 supports to use of a custom CA certificate and key when installing a Robin CNP cluster. You can get the custom CA certificate and key from an external trusted CA or a dedicated internal public key infrastructure service. After getting the custom CA certificate and its key, make sure that the custom CA certificate and its key must be configured as an intermediate CA certificate. The intermediate CA certificate is the signing certificate that signs the other certificates generated by the cluster.
You must specify the --ca-cert-path and --ca-key-path options with the Robin installation command when installing the first node of the cluster.
23.1.4. Improvements¶
23.1.4.1. Option to configure a single node cluster¶
Robin CNP v5.3.13 provides the --single-node-cluster option to configure a single node cluster. You can use this option as part of the install command.
Note
After using the --single-node-cluster option, you cannot add new nodes to the cluster.
The following are open TCP network ports available for a single node cluster:
22
6443
29442
29443
29445
29449
23.1.4.2. Option to rename the Robin default Calico IP-Pool name¶
Starting from Robin CNP v5.3.13, you can rename the Robin default Calico IP-Pool robin-default as per your requirement. To use the custom name for the Robin default Calico IP-Pool, you must specify the name in the following command option when installing the Robin CNP.
--robin-default-ippool-name
If you do not specify the custom name, Robin CNP uses the robin-default name for the Robin default Calico IP-Pool.
Note
You can use this command option only during installation.
23.1.4.3. Support to use systemd as cgroup driver¶
Robin CNP v5.3.13 provides the support to use systemd as cgroup driver. You must use the following command option when installing Robin CNP v5.3.13 as part of the install command:
--cgroup-driver=systemd
Note
The --cgroup-driver is an optional command option. if you do not use the --cgroup-driver=systemd, CNP uses the default cgroupfs for the cgroup driver.
23.1.4.4. Support for Pod creation when SRIOV pfs is down¶
Robin CNP v5.3.13 supports the Pod creation even when SRIOV pfs is down.
You need to include ignore_iface_state true as a network annotation.
For bundle application, you can pass this in the manifest.yaml or use the input.yaml file.
In the manifest.yaml file, you can provide it under the network field.
Example:
net:
- name: public
- name: sr1
ignore_iface_state: true
trust: 'on'
- name: sr2
ignore_iface_state: true
trust: 'off'
In the input.yaml file you can provide under IP Pools field.
Example:
appname: "ovs-staticips-app"
media: HDD
roles:
- name: server
multinode_value: 2
ippools:
- ippool: sriovpool1
ignore_iface_state: True
For k8/helm based application, you can provide the following annotation:
Example:
robin.io/networks: '[{"ippool": "sriovpool1", "ignore_iface_state": "True"}]
23.1.4.5. Support for Pod creation when MacVLAN and IPVLAN IP-Pools master interface is down¶
Robin CNP v5.3.13 supports the Pod creation for MacVLAN and IP VLAN based IP-Pools even when the master interface is down.
You need to include ignore_iface_state true as a network annotation.
For bundle applications, you can pass this in the manifest.yaml or use the input.yaml file. For examples, refer to the above note.
23.1.4.6. Support for jinja variables in Bundle manifest file for PDV section¶
Starting with Robin CNP 5.3.13, the Robin Bundle manifest file supports jinja variables in the PDV section. This enables the mount path to enable PDV to be set in the manifest file and these mount paths are then auto-populated in the UI. Prior to this feature support, the PDV mount paths were fixed.
The following are supported jinja variables:
namespace
user
tenant
resourcepool
Note
Appropriately named PDVs must exist in the namespace.
Example:
Update the bundle manifest file by adding a pdvs section at the same indentation level as storage and compute like so:
pdvs:
- name: "{{namespace}}-data"
mount_path: "/data/{{namespace}}-data"
- name: "{{namespace}}-data-2"
mount_path: "/data/{{namespace}}-data-2"
This results in the following auto-filled PDV section in the GUI:
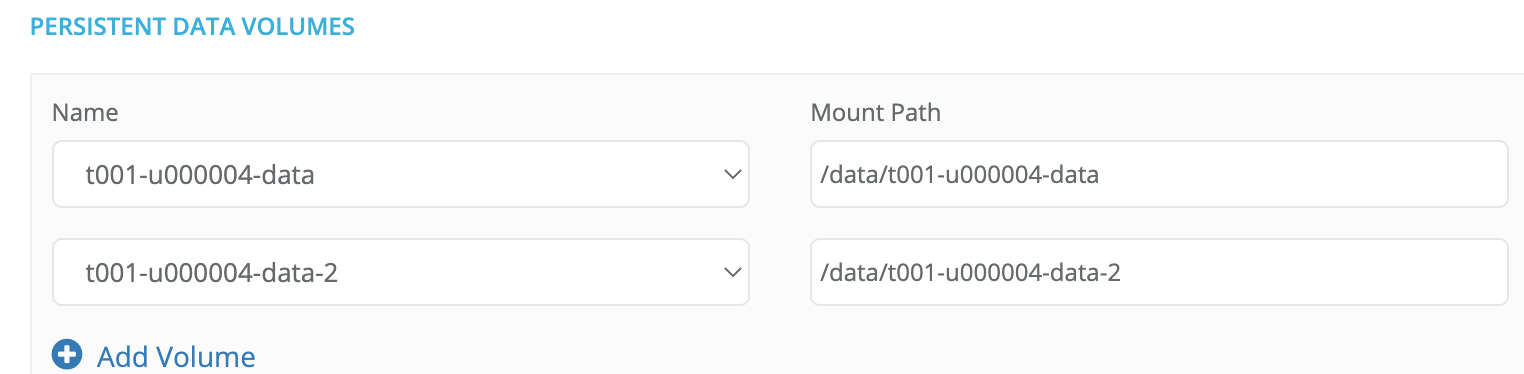
Note the jinja variable substitution where {{namespace}} has been substituted with the current namespace, mainly t001-u000004.
Also note the autofilled mount paths as specified by the mount_path variable.
23.1.5. Fixed Issues¶
Reference ID |
Description |
|---|---|
PP-27464 |
Nessus scans discovered a vulnerability of enabled debugging functions like HTTP TRACE and TRACK. This issue is fixed. |
PP-27590 |
The GPU discovery and the Chargeback price update issues are fixed. |
23.1.6. Known Issues¶
Reference ID |
Description |
|---|---|
PP-28026 |
Symptom When a license expires on a cluster, the following info type event is generated without an alert:
|
PP-28138 |
Symptom When upgrading from Robin CNP 5.3.11-HF3 to 5.3.13, the post Robin Upgrade actions on the primary master node in the cluster might fail as one of the Nodes in the cluster is in the NotReady state. Workaround For workaround steps, see Troubleshooting a Robin Cluster Node with the NotReady State. |
PP-28027 |
Symptom The SELinux status changes to permissive from enforcing when using Centos docker image with Workaround Do not use |
PP-25381 |
Symptom The Robin CNP 5.3.13 provides an option in the UI to create Application Ephemeral Volume (AEVs) using faultdomain(rack). The option is displayed in the UI incorrectly. Robin CNP does not support rack fault domain for AEVs. |
PP-28167 |
Symptom HA failover did not happen immediately after the master node reboot. Workaround If you need to reboot (offline) the current master node, you need to force the master node to release the MASTER lock, and make sure the other two Manager nodes are ONLINE and Ready. Releasing the MASTER lock results in a master failover and one of the slaves will grab the MASTER lock and transition to become the master. Use the following command to release the MASTER lock: # robin host release-master-lock <master_node_hostname> --force
|
PP-28244 |
Symptom When you deploy an application using Robin CNP, the deployed application UI instance may not be accessible from Robin UI. However, the application functions normally and you can use the kubectl CLI to access the application. Workaround Use the following command to access the application console. # kubectl exec -it -n <app-namespace> <app-name>
|
PP-28195 |
Symptom On the Applications page of the Robin CNP UI, the Usage column for the Chargeback report appears blank. (Applications> Applications> <app page>> Chargeback). Workaround You can view the usage of the application from the Chargeback menu option on the left side menu bar of the Robin CNP UI. |
23.1.7. Appendix¶
23.1.7.1. Troubleshooting a Robin Cluster Node with the NotReady State¶
The following content is the workaround for PP-28138.
A Robin node in a cluster might go into the NotReady state when an RWX PVC’s mount path is not responding. This issue could occur due to several internal Kubernetes known issues.
The RWX PVC’s mount path may not respond due to the following issues/symptoms on your cluster. You can troubleshoot these issues and bring back the node to the Ready state. This document section provides troubleshooting steps for the following issues:
NFS server’s service IP address entry in the conntrack table might go into
SYN_SENTorTIME_WAITstateNFS Servers may not be ready
NFS Server Failover Issues
I/O hangs on the volume
With Robin v5.3.11 HF2, you might notice the NotReady state issue when you are upgrading from Robin v5.3.11 HF1 to Robin v5.3.11 HF2.
Troubleshoot NFS Server’s service IP address entry in the conntrack table in SYN_SENT or TIME_WAIT state
The Robin node could be in the NotReady state if the NFS Server’s service IP address entry in the conntrack table in SYN_SENT or TIME_WAIT.
The following steps enable you to troubleshoot this issue and bring the node to the Ready state.
Run the following command to know if your node is in the
NotReadystate when you notice any of the above-mentioned symptoms:
# kubectl get node <node name>
Example:
# kubectl get node hypervvm-61-46
NAME STATUS ROLES AGE VERSION
hypervvm-61-46 NotReady <none> 25h v1.21.5
Run the following command and grep the NFS server mount paths:
# mount|grep :/pvc
Copy the mount paths for verification from the command output.
Run the following command to check the status of the mount path:
# ls <nfsmount>
Example:
# ls /var/lib/kubelet/pods/25d256d5-e6cc-4865-a3ee-88640e0d1fc8/volumes/kubernetes.io~csi/pvc-210829ca-96d4-4a12-aab8-5646d087054d/mount
Note
If any mount paths do not respond or hang, you must check the status of conntrack.
You need the service IP of the NFS Server Pod for checking conntrack status.
Run the following command to get the NFS server Pod service IP address:
# mount|grep <pvc name>
Example:
# mount|grep pvc-210829ca-96d4-4a12-aab8-5646d087054d
[fd74:ca9b:3a09:868c:172:18:0:e23e]:/pvc-210829ca-96d4-4a12-aab8-5646d087054d on /var/lib/kubelet/pods/25d256d5-e6cc-4865-a3ee-88640e0d1fc8/volumes/kubernetes.io~csi/pvc-210829ca-96d4-4a12-aab8-5646d087054d/mount type nfs4 (rw,relatime,vers=4.0,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp6,timeo=600,retrans=2,sec=sys,clientaddr=fd74:ca9b:3a09:868c:10:9:82:127,local_lock=none,addr=fd74:ca9b:3a09:868c:172:18:0:e23e)
Verify if the conntrack entry state using NFS server Pod IP address by running the following command:
# conntrack -L -d <NFS server Pod IP address>
Note
If you notice the conntrack entry state as SYN_SENT or TIME_WAIT, you need to delete the entry from conntrack table entries to allow connections to the NFS service.
Example:
# conntrack -L -d fd74:ca9b:3a09:868c:172:18:0:e23e
13tcp 6 110 SYN_SENT src=fd74:ca9b:3a09:868c:10:9:82:127 dst=fd74:ca9b:3a09:868c:172:18:0:e23e sport=980 dport=2049 [UNREPLIED] src=fd74:ca9b:3a09:868c:172:18:0:71d4 dst=fd74:ca9b:3a09:868c:10:9:82:127 sport=2049 dport=614 mark=0 use=1
14conntrack v1.4.4 (conntrack-tools): 1 flow entries have been shown.
Run the following command to delete the
SYN_SENTorTIME_WAIT:
# conntrack -D -d <NFS server Pod IP address>
Example:
# conntrack -D -d fd74:ca9b:3a09:868c:172:18:0:e23e
18tcp 6 102 SYN_SENT src=fd74:ca9b:3a09:868c:10:9:82:127 dst=fd74:ca9b:3a09:868c:172:18:0:e23e sport=980 dport=2049 [UNREPLIED] src=fd74:ca9b:3a09:868c:172:18:0:71d4 dst=fd74:ca9b:3a09:868c:10:9:82:127 sport=2049 dport=614 mark=0 use=1
19conntrack v1.4.4 (conntrack-tools): 1 flow entries have been deleted.
Note
After deleting the SYN_SENT or TIME_WAIT state from the conntrack, you should be able to access the NFS mount path.
Run the following command to verify mount path status.
# ls /var/lib/kubelet/pods/25d256d5-e6cc-4865-a3ee-88640e0d1fc8/volumes/kubernetes.io~csi/pvc-210829ca-96d4-4a12-aab8-5646d087054d/mount
Additional Troubleshooting Checks
If you have verified the NFS Server’s service IP address entry in the conntrack table in SYN_SENT or TIME_WAIT status and still your node is in the NotReady state, you need to perform additional checks to troubleshoot the issue.
The following are some additional checks for troubleshooting the issue:
Check NFS Exports Status
Check NFS server failover Status
Check NFS server Pod is provisioned.
Check NFS Exports Status
All NFS exports must be in the READY state.
To check the NFS exports status, run the following command:
# robin nfs export-list
Example:
# robin nfs export-list
+--------------+-----------+------------------------------------------+---------------------+-----------------------------------------------------------------------+
| Export State | Export ID | Volume | NFS Server Pod | Export Clients |
+--------------+-----------+------------------------------------------+---------------------+-----------------------------------------------------------------------+
| READY | 7 | pvc-9b1ef05e-5e4a-4e6a-ab3e-f7c95d1ae920 | robin-nfs-shared-9 | ["hypervvm-61-48.robinsystems.com","hypervvm-61-43.robinsystems.com"] |
+--------------+-----------+------------------------------------------+---------------------+-----------------------------------------------------------------------+
Note
If NFS exports are not in the READY state, make sure the NFS server failover is enabled. Generally, it is enabled by default.
Check NFS server failover Status
The NFS Server failover status is by default enabled. However, you should check for confirmation and enable it if it is disabled.
To check NFS server failover status, run the following command:
# robin config list nfs|grep failover_enabled
nfs | failover_enabled
Check NFS server Pod is provisioned
To check whether NFS server Pod is provisioned or not, run the following command:
# robin job list|grep -i NFSServerPodCreate|tail
Note
If all of these checks are fine, then it could be a bug in the NFS Server Failover. To troubleshoot the NFS Server failover issue, see Troubleshoot NFS Server Failover Issues.
Troubleshoot NFS Server Failover Issues
A node could go to the NotReady state due to NFS Server failover issues as well, apart from other issues mentioned in this section.
Note
You can use the following steps even if your NFS Server has no issues, however, the PVC mount path is hung.
Before you troubleshoot the NFS Server failover issues, check the Troubleshoot NFS Server’s service IP address entry in the conntrack table in SYN_SENT or TIME_WAIT state and Additional Troubleshooting Checks.
To fix the NFS server failover issues, complete the following steps:
Run the following command to check if any NFS exports are in the
ASSIGNED_ERRstate and identify corresponding PVCs:
# robin nfs export-list
Run the following command to note the replica count in the deployment or StatefulSet:
# kubectl get all -n <ns>
Example:
# kubectl get all -n <ns>
...
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/app1 2/2 2 2 27h
NAME DESIRED CURRENT READY AGE
replicaset.apps/app1-5cbbc6d9db 2 2 2 27h
Run the following command to scale the application Pods that use those PVCs to 0:
Note
Do not delete the application.
Scaling down the application Pods will make sure that new Pods do not come up and results in the NFS exports being cleared.
# kubectl scale --replicas=0 <deployment/statefulset> -n <ns>
Run the following command to check all NFS exports are healthy:
# robin nfs export-list
(Optional) Run the following command on the hung paths if you notice some mount paths are still hung:
# umount -f -l <hung nfs mount path>
Run the following command to check the node status:
# kubectl get node <node name>
Note
If you notice the node is still not showing the Ready state, wait for 2 minutes for kubelet to refresh the status.
If the status is still not showing Ready, stop and start kubelet by running following commands:
# systemctl stop kubelet
#systemctl start kubelet
Check the node status again. If the status is
Ready, then go to the last step.
# kubectl get node <node name>
If the node is still not in the
Readystate or flapping betweenReady/NotReadyand you do not see any Pods in k8s that are using the RWX PVC, it may be Pods are deleted by force from Kubernetes.
In this case, k8s does not see Pods, but Docker is still hanging on to those Pods. THIS IS A RARE CASE and is hit only when Pods are deleted forcefully.
In this case, run the following commands:
# docker rm <>
# systemctl restart docker
Run the following command to check the node status:
# kubectl get node <node name>
The node should be in the Ready state.
Run the following command to scale up the application Pods back to the original count that you noted earlier:
# kubectl scale --replicas=<n> <deployment/statefulset> -n <ns>
23.2. Robin Cloud Native Platform v5.3.13 HF1¶
The Robin Cloud Native Platform (CNP) v5.3.13 HF1 release has fixed issues and known issues.
Release Date: 21 November 2022
23.2.1. Infrastructure Versions¶
The following software applications are included in this CNP release.
Software Application |
Version |
|---|---|
Kubernetes |
1.21.5 |
Docker |
19.03.9 |
Prometheus |
2.16.0 |
Prometheus-adapter |
0.9.1 |
Node-exporter |
1.1.2 |
Calico |
3.12.3 |
HA-Proxy |
1.5.18 |
PostgreSQL |
9.6.24 |
Grafana |
6.5.3 |
23.2.2. Upgrade Path¶
The following are the supported upgrade paths for Robin CNP v5.3.13 HF1:
Robin v5.3.11 (HF2) to Robin v5.3.13 (HF1)
Robin v5.3.11 (HF4) to Robin v5.3.13 (HF1)
23.2.3. Fixed Issues¶
Reference ID |
Description |
|---|---|
PP-29140 |
When scaling out an application using the Robin CNP UI, the Scale Out screen does not appear if the Bundle manifest file has an environment variable of type:number. This issue is fixed. |
PP-29107 |
The exclusive mode of access for storage devices required by Robin CNP storage modules failed on multiple storage devices due to some transient process. So, the storage modules immediately marked the devices as faulted, resulting in downtime for an app. In 5.3.13 HF1, this issue is fixed by enabling Robin CNP storage modules to retry the exclusive access mode after a few seconds before marking the devices as faulted. |
PP-29083 |
A network interface for the pod is missing when deploying an application with any of the following interfaces: SRIOV, DPDK & MACVLAN. This issue is fixed. |
PP-29042 |
The memory usage on Robin worker pods is increasing consistently due to a memory leak on the cluster. This issue is fixed. |
PP-28702 |
The Border Gateway Protocol (BGP) peering is failing on the Robin cluster due to an issue with Calico v3.12.3. In Robin 5.3.13 HF1 this issue is fixed by supporting Calico v3.21.5. You must upgrade to Calico v3.21.5 if you need to use the BGP protocol. Note Note: Contact the Robin customer support team if you want to upgrade to Calico v3.21.5. |
PP-28684 |
When the RWX volume contains a large number of files (over 500k), containers are stuck in the ContainerCreating status, and the node plugin pod crashes with the out-of-memory (OOM) issue. This issue is fixed. |
PP-28267 |
IP-Pool creation for the OVS driver fails with the following error: “ValidatingWebhookConfiguration” for ippool “ippoolcr-validating-webhook” was not created. This issue is fixed. |
23.2.4. Known Issues¶
Reference ID |
Description |
|---|---|
PP-29150 |
Symptom When creating an SRIOV or OVS IP-Pool with VLAN, Robin CNP mistakenly allows the creation of the SRIOV or OVS IP-Pool if one of them has configured VLAN for its interface at the host level. For example, in a scenario where you have created an SRIOV IP pool with VLAN, and the VLAN is added to the SRIOV interface at the host level. At the same time, if you create an OVS IP Pool with the same VLAN but without adding VLAN for the OVS interface at the host level, the OVS IP pool creation succeeds without any error. However, in this example, when you try to deploy the pod using the OVS IP pool, the Pod deployment fails at the ContainerCreating status without any error message. Workaround Add the VLAN on the host for the corresponding interface and redeploy the Pod. |
PP-29109 |
Symptom Robin CNP 5.3.13 HF1 does not support Application Ephemeral Volume (AEV). Due to AEV nonsupport, operations involved with AEVs will fail. |
23.2.5. Technical Support¶
Contact Robin Technical support for any assistance.
23.3. Robin Cloud Native Platform v5.3.13 HF2¶
The Robin Cloud Native Platform(CNP) v5.3.13 HF2 release has fixed issues and a known issue.
Release Date: 15 January 2023
23.3.1. Infrastructure Versions¶
The following software applications are included in this CNP release.
Software Application |
Version |
|---|---|
Kubernetes |
1.21.5 |
Docker |
19.03.9 |
Prometheus |
2.16.0 |
Prometheus-adapter |
0.9.1 |
Node-exporter |
1.1.2 |
Calico |
3.12.3 |
HA-Proxy |
1.5.18 |
PostgreSQL |
9.6.24 |
Grafana |
6.5.3 |
23.3.2. Upgrade Paths¶
The following is the supported upgrade path for Robin CNP v5.3.13 HF2:
Robin v5.3.11 (HF2) to Robin v5.3.13 (HF2)
Robin v5.3.11 (HF4) to Robin v5.3.13 (HF2)
Robin v5.3.13 (HF1) to Robin v5.3.13 (HF2)
Note
When upgrading to Robin CNP v5.3.13 HF2, if your existing setup has a Vault integrated, you must use the following parameter along with the upgrade command: --vault-addr=<vault address>.
23.3.3. Fixed Issues¶
Reference ID |
Description |
|---|---|
PP-29519 |
The issue of Robin CNP taking more time to create network attachment definition as part of Pod creation is fixed. |
PP-29538 |
The issue where the entire annotation is ignored by the Robin planner when there is only one node in a Resource pool and more than one SRIOV interfaces in |
PP-29539 |
The issue of the network attached definition in Pods not being cleared when one of the two deployments is deleted is fixed. |
PP-29541 |
On a DeploymentSet with more than six replicas and ten interfaces per replica, if you delete the DeploymetSet before its creation, it leaves residual network attached definitions. This issue is fixed. |
PP-29535 |
After the upgrade, creating a KVM App may result in a failure with the error message list index out of range. This issue is fixed. |
PP-29360 |
When you add a secondary DPDK-based IP-Pool, routes are programmed by Robin CNP (robin-ipam) erroneously. As a result, Pods are not coming up and failing at the |
PP-29556 |
As the Virtual Functions (VF) count in an SR-IOV pool is not upgrading correctly when you try to discover a host by running the following command: robin host probe – rediscover, the host discovery process fails without any message. This issue is fixed. |
PP-29558 |
When you create a Pod, the Pod is failing to come up online and you can see errors in the logs. This issue is fixed |
PP-29534 |
With the |
23.3.4. Known Issues¶
Reference ID |
Description |
|---|---|
PP-29549 |
Symptom When you use This causes Border Gateway Protocol (BGP) peering for that node to use the VIP. If the VIP is moved, the original node will no longer be a part of the BGP peer list, resulting in connectivity failure for Pods running on that node. Workaround Edit the
Note This will result in all Calico Pods restarting and BGP peering will be re-established. |
PP-29577 |
Symptom When you delete an SR-IOV pod and restart the Robin server, you might observe the SR-IOV deployment pods are in the create and terminate loop states. |
PP-29582 |
Symptom When you stop and start the Robin server during pod deployment, the Robin network annotations might be ignored. |
23.4. Robin Cloud Native Platform v5.3.13 HF3¶
The Robin Cloud Native Platform (CNP) v5.3.13 HF3 release has new features and fixed issues.
Release Date: 17 August 2023
23.4.1. Infrastructure Versions¶
The following software applications are included in this CNP release.
Software Application |
Version |
|---|---|
Kubernetes |
1.21.5 |
Docker on CentOS |
19.03.9 |
Docker on Rocky Linux |
20.10.8 |
Prometheus |
2.16.0 |
Prometheus-adapter |
0.9.1 |
Node-exporter |
1.1.2 |
Calico |
3.12.3 |
HA-Proxy |
1.5.18 |
PostgreSQL |
9.6.24 |
Grafana |
6.5.3 |
23.4.2. Upgrade Paths¶
The following are the supported upgrade path for Robin CNP v5.3.13 HF3:
Robin V5.3.11 (HF2) to Robin v5.3.13 (HF3)
Robin v5.3.13 (HF2) to Robin v5.3.13 (HF3)
Robin v5.3.13 (HF2+PP) to Robin v5.3.13 (HF3)
Note
When upgrading to Robin CNP v5.3.13 HF3, if your existing setup has a Vault integrated, you must use the following parameter along with the upgrade command: --vault-addr=<vault address>.
23.4.3. New Features¶
23.4.3.1. Backup and restore for Helm applications¶
Robin CNP v5.3.13 HF3 supports backup and restore of Helm applications. It enables you to securely store applications on local clusters and remote locations, such as Amazon S3 Object Store and MiniIO buckets.
You can create an application from the backup using the following command. For all other backup and restore operations, you can use the existing backup and restore commands.
# robin app create from-backup <app name> <backup ID> --same-name-namespace --namespace <namespace>
Note
When creating a Helm app from the backup, the app name must be the same as the original name and it must be deployed on the same Namespace.
Example
# robin app create from-backup postgres1 3beae40a310311eeb54edb39ed734caf --same-name-namespace --namespace t001-u000004 --start-hydration
23.4.3.2. Support of soft affinity¶
Robin CNP v5.3.13 HF3 supports the soft affinity feature with a few limitations.
In Kubernetes, the soft affinity feature refers to a way of guiding the Kubernetes Scheduler to make a decision about where to place Pods based on preferences, rather than strict requirements. This preference helps to increase the likelihood of co-locating certain Pods on the same node, while still allowing the Kubernetes Scheduler to make adjustments based on resource availability and other constraints. For more information, see Affinity and anti-affinity.
Limitations
The following are the limitations of support for soft affinity and anti-affinity support:
These operators are not supported: DoesNotExist, Gt, and Lt.
Multiple weight parameters for node and Pod affinity are not supported.
Soft anti-affinity doesn’t check or match for the label selector coming from a different Deployment.
During a complete cluster restart, if all nodes are not up at the same time, Pods will not be spread across nodes with soft anti-affinity.
After a Pod restart, it might not come back on the same node.
Post downsizing the number of replicas in a Deployment, soft Pod anti-affinity might not delete the Pods in the same order as creation.
23.4.3.3. Support for MTU parameter for IP Pools¶
Starting from Robin CNP 5.3.13 HF3, you can provide the maximum transmission unit (MTU) when creating an IP pool. The default MTU is 1500.
23.4.4. Fixed Issues¶
Reference ID |
Description |
|---|---|
PP-29201 |
When restoring an app from a source to a destination cluster, the restore operation appends the source application name to the destination application name while creating the Kubernetes objects on the destination cluster. This issue is fixed. |
PP-30052 |
The issue of Robin CNP Scheduler not calculating the guaranteed CPU utilization and scheduling the Pods on overutilized nodes is fixed. |
PP-30053 |
The issue of hard affinity not being honored in Robin CNP is fixed. |
PP-30325 |
In certain cases, when the robin-server is busy, robin-annotations are ignored and the Pods would come up with only the default Calico interface. This issue is fixed. |
PP-30413 |
When importing LDAP users from an LDAP group into Robin CNP using the The below error has occurred:
One or more errors when importing members from LDAP group 'RCM_GROUP':
'list' object has no attribute 'split'
This issue is fixed. |
PP-30448 |
Starting from Robin CNP v5.3.13 HF3, the |
PP-30611 |
When the monitor server in Robin CNP fails to report to the robin-server, it waits for a long time before attempting to send the next report. As a result, the heartbeat misses for a long time and it results in host probe jobs. This issue is fixed. |
PP-30969 |
The issue of the CNP database going back in time during the Robin CNP master reboot or failover is fixed. |
PP-31079 |
Robin CNP v5.3.13 installation with Hashicorp Vault using FQDN for the Vault address was failing. This issue is fixed. |
PP-31452 |
Robin CNP v5.3.13 installation with Hashicorp Vault was failing with an error because of a delay in loading the routes for Calico CNI. The kubectl logs command for pre-job shows the following error: {{dial tcp: i/o timeout or Route missing }}
This issue is fixed. |
PP-31530 |
A KVM bundle app with secondary IP-Pools fails to restore from its backup with the following error: Secondary IP Pool does not have a primary IP Pool configured
This issue is fixed. |
23.4.5. Known Issues¶
Reference ID |
Description |
|---|---|
PP-31591 |
After upgrading from Robin CNP v5.3.11 HF2 to Robin CNP v5.3.13 HF3, if you are adding new ranges to an existing IP Pool, the following error occurs: ERROR - Failure occurred during IP Pool update operation:
Command 'kubectl apply -f /var/run/robintmp/tmpoed2wef2
--kubeconfig=/root/.kube/config' failed with return code 1.``
Workaround You need to manually add all the existing ranges for an IP Pool using the following command: kubectl edit ripp <name of the ip pool>
Sample Spec spec:
action: sync
available: "32"
driver: sriov
gateway: fd74:ca9b:3a09:8718:10:9:0:1
ifcount: 1
macvlan_mode: bridge
name: sriov-8718
prefix: 64
ranges:
-fd74:ca9b:3a09:8718:0010:0009:0001:0001-0020
used: "0
|
23.4.6. Technical Support¶
Contact Robin Technical support for any assistance.