19. High Availability¶
19.1. High availability of the Kubernetes control plane¶
A Kubernetes cluster having a single master node is vulnerable should the master node ever fail. The master node manages the etcd database containing control data for the cluster. Key Kubernetes services, such as the API server, controller manager, and scheduler also run on the master node. Without the master node, it’s not possible to access information about currently deployed applications, allocated resources, etc. It’s also not possible to create new resources such as Pod, services, configmaps, etc.
In a high availability (HA) configuration, the Kubernetes cluster is configured with a minimum of three master nodes. The etcd database containing cluster control data is replicated across each of the master nodes. Key Kubernetes services also run on each of the master nodes. Should one of the master nodes fail, the remaining two will ensure the integrity of cluster control data and that the cluster is kept up and running.
Note that a highly available Kubernetes cluster requires at least two master nodes. This has to do with the consensus algorithm employed by etcd. To have a quorum, a minimum of half plus one masters must be present. This prevents a “split brain” scenario if a network partition occurs. Only the half with a quorum of master nodes will continue on.
19.1.1. High availability of the Kubernetes API server¶
Robin Platform uses keepalived and HAProxy services to provide high availability access to the Kubernetes API server.
Keepalived
The keepalived service is responsible for managing a Virtual IP address (VIP) where all requests to the Kubernetes API server are sent.
The keepalived service, which runs on each of the master nodes, implements the Virtual Router Redundancy Protocol (VRRP), a multicast protocol. All nodes in a VRRP cluster (“physical routers”) must be on the same subnet. Together, they form a single, “virtual router” for managing a given VIP.
It’s possible for multiple virtual routers to exist on the same subnet. For this reason, each VRRP cluster is configured with a unique (for a given subnet) “Virtual Router ID” (VRID). The use of a VRID ensures that all packets for a given VRRP cluster are only seen by the physical routers from that cluster. A VRID is an arbitrary numeric value from 1-255.
A VIP and VRID needs to be selected before installing the first master node in a Robin Platform cluster (they will be included on the command line). Care needs to be taken that he selected VIP is not already in use and that the VRID has not been used with another VRRP cluster in the same subnet (keepalived is not the only utility that implements the VRRP protocol).
The keepalived and HAProxy services are configured during the installation of Robin Platform. With the installation of each subsequent master node (up to a total of 3), the node will be added to the keepalived VRRP cluster, in addition to Kubernetes and Robin Platform clusters.
When installation of the first master node is complete, the VIP will be active on that node. If that node goes down, or gets partitioned from the rest of the cluster, the VIP will be brought up on another master node.
HAProxy
The HAProxy service is responsible for redirecting API server requests to instances of the API server running on each of the master nodes. Since the API server is stateless, requests are redirected in a round-robin manner.
The haproxy service also runs on each of the master nodes. But only the instance running on the node with the VIP exposed sees any action. The other instances wait for when the VIP fails-over to their respective nodes.
19.2. High Availability of the Robin control plane¶
The Robin CNP management plane is comprised of services that manage the physical resources of a cluster and the applications deployed to the cluster. These management services don’t run directly on the host. Instead, they run in containers deployed on each node in the cluster.
Several services are active on all nodes in the cluster, and there are control plane services that run inside Pods on various nodes of the cluster. These services are responsible for handling the deployment of application resources on the node and for monitoring the health of the node.
The following illustration explains the Robin CNP Architecture:
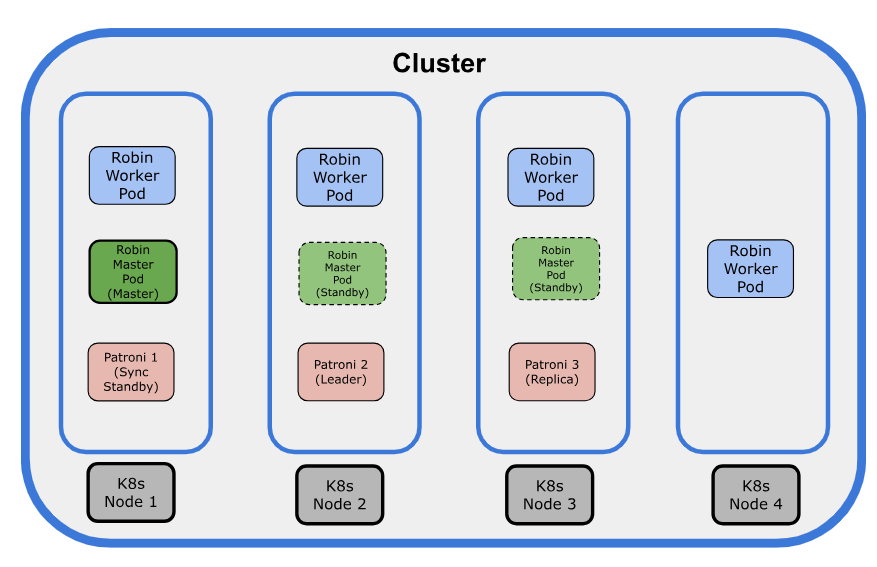
The following points explain the architecture:
The
robin-masterPods are deployed as a Deployment. Depending on the number of master nodes in the cluster, therobin-masterPods can range from a minimum of one for a single-node cluster to a maximum of three.If there are three replicas, only one of the
robin-masterPods plays the role of the Master role (Leader), and the remainingrobin-masterPods remain as Standby.Robin CNP utilizes the Kubernetes Lease mechanism to manage the Master role. The
robin-masterlease is obtained on a first-come, first-served basis. Therobin-masterPod that secures the lease becomes the Master, while the remainingrobin-masterPods take on the role of Standby. If the node hosting therobin-masterPod (Master role) fails, one of the Standby Pods will acquire the lease and become the new Master. For more information on Kubernetes Lease mechanism, see, https://kubernetes.io/docs/concepts/architecture/leases/The default lease duration and lease timeout for the
robin-masterPod are set to 15 seconds. Under normal conditions, therobin-masterPod renews the lease before it expires. - If the lease is not renewed by the deadline, one of the Standby Pods will acquire the lease and assume the master role. If there is only onerobin-masterpod, then there is no failover. When there is a failure, the control plan must wait for a replacementrobin-masterPod to spin up and become ready.The
kubeletservice, running on each node, monitors all Pod containers deployed on that node. If any container fails, the kubelet will restart it. Therobinrcmcontainer within therobin-masterPod has a livenessProbe configured to run periodically. If this probe ever fails, the kubelet will restart the robinrcm container.
The robin-master Pod runs only the following master services:
Consul Server
HTTPD
PHP and FPM
Robin Authentication server
Robin Bootstrap
Robin DB connect
Robin Event server
Robin Master
Robin Node monitor
Robin Server
Sherlock
Stormanager Server
The
robin-workerPods are deployed as a DaemonSet and therobin-workerPods run only the agent services, such as robin-agent and monitor-server.The robin-iomgr Pods are deployed as a DaemonSet and are responsible for handling I/O requests from the application.
In Robin CNP, Patroni is used as an independent PostgreSQL HA cluster, and it is deployed as part of installation. As the PostgreSQL HA is managed outside
robin-masterPods, its failover is not tied to Robin control-plane services failover.A maximum of the three Patroni instances (Pods) are present in a cluster. The Patroni HA cluster has one leader (Leader), one synchronous replica (Sync Standby), and one asynchronous replica (Replica). All Patroni replicas are configured with permanent replication slots.
The Patroni cluster will automatically scale up when additional nodes are added to the node pool later.
The
/devbind mount from the host into Robin Pods is only needed forrobin-worker,robin-iomgr, andcsi-nodeplugin-robinPods.With control plane and data plane separation, master services will not have access to /dev.
The Robin master services provide access to user interfaces (UI/CLI/API) to CNP users. Due to this, no privileged Pod will take up any user APIs, reducing the attack surface significantly.
There are two replicas for the Robin CSI provisioner, attacher, resizer, and snapshotter Pods. Having two replicas reduces the time window of unavailability for CSI Pods if any node goes down.
19.3. Robin Patroni Monitor¶
The Robin Patroni Monitor feature monitors the status of the Patroni instances (Pods) in a cluster and provides events. The feature is automatically enabled on clusters running Robin CNP v5.5.0.
The Robin CNP architecture includes a highly available PostgreSQL cluster managed by Patroni, referred to as the Patroni Cluster.
To ensure high availability (HA), Patroni maintains three copies of its database, meaning a maximum of three Patroni instances (Pods) are present in a cluster at any given time.
The Patroni HA cluster consists of one Leader, one synchronous replica (Sync Standby), and one asynchronous replica (Replica). When the Leader Patroni instance goes down, the Sync Standby instance is promoted to become the new leader.
A Patroni cluster might become unavailable for a number of reasons. To monitor the status of the Patroni cluster, Robin CNP provides the Robin Patroni Monitor feature, which generates the events as required.
By default, the Robin Patroni Monitor feature is enabled, and it cannot be disabled.
19.3.1. View Status of Patroni cluster¶
You can view the status of the Patroni cluster, which displays the status of all three Patroni replicas. The Patroni replicas can have in one of the following statuses:
Ready
Not Ready
Failed
It also displays the status of the Robin Patroni Monitor feature. The Ready parameter always set to True because this feature is enabled by default.
Run the following command to view the status of the Patroni cluster:
# robin patroni status
--wide
--full
--json
|
Display additional attributes about the Patroni Cluster. |
|
Display all information about the Patroni Cluster. |
|
Output in JSON. |
Note
The patronictl list command also displays similar information about the Patroni cluster.
Example
# robin patroni status
Robin Patroni Monitor:
Deployment:
Deployed: True
Available: True
Ready: True
Pod:
Pod Deployed: True
Pod Status: Running
Robin Patroni Cluster:
Hostname | PodIP | Role | State | TL | Lag
----------------+---------------+--------------+-----------+----+-----
robin-patroni-0 | 192.0.2.190 | Sync Standby | streaming | 3 | 0
robin-patroni-1 | 192.0.2.180 | Replica | streaming | 3 | 0
robin-patroni-2 | 192.0.2.175 | Leader | running | 3 |
The following example is with the -- wide.
# robin patroni status --wide
Robin Patroni Monitor:
Deployment:
Deployed: True
Available: True
Ready: True
Pod:
Pod Deployed: True
Pod Status: Running
Robin Patroni Cluster:
Hostname | NodeName | HostIP | PodIP | WAL Offset | Role | State | TL | Lag
----------------+--------------+-------------+---------------+------------+--------------+-----------+----+-----
robin-patroni-0 | node-8-test | 192.0.2.192 | 192.169.3.190 | 0/8544178 | Sync Standby | streaming | 3 | 0
robin-patroni-1 | node-8-test1 | 192.0.2.198 | 192.169.4.4 | 0/8544178 | Replica | streaming | 3 | 0
robin-patroni-2 | node-8-test2 | 192.0.2.202 | 192.169.0.175 | 0/8544178 | Leader | running | 3 |
The following example is with the -- full.
# robin patroni status --full
Robin Patroni Monitor:
Deployment:
Deployed: True
Available: True
Ready: True
Pod:
Pod Deployed: True
Pod Status: Running
Robin Patroni Cluster:
Hostname | NodeName | HostIP | PodIP | WAL Offset | Role | State | TL | Lag
----------------+--------------+-------------+---------------+------------+--------------+-----------+----+-----
robin-patroni-0 | node-8-test | 192.0.2.192 | 192.169.3.190 | 0/85447A0 | Sync Standby | streaming | 3 | 0
DCS Last Seen: September 20, 2024 06:28:41
Location: 139741088
Replication State: streaming
Replayed Location: 139741088
Replayed WAL Offset: 0/85447A0
Hostname | NodeName | HostIP | PodIP | WAL Offset | Role | State | TL | Lag
----------------+--------------+-------------+-------------+------------+---------+-----------+----+-----
robin-patroni-1 | vnode-8-test1| 192.0.2.198 | 192.169.4.4 | 0/85447A0 | Replica | streaming | 3 | 0
DCS Last Seen: September 20, 2024 06:28:37
Location: 139741088
Replication State: streaming
Replayed Location: 139741088
Replayed WAL Offset: 0/85447A0
Hostname | NodeName | HostIP | PodIP | WAL Offset | Role | State | TL | Lag
----------------+--------------+-------------+---------------+------------+--------+---------+----+-----
robin-patroni-2 | vnode-8-test2| 192.0.2.202 | 192.169.0.175 | 0/85447A0 | Leader | running | 3 |
DCS Last Seen: September 20, 2024 06:28:37
Location: 139741088
19.3.2. View Events in robin-patroni-monitor Pod¶
You can view the Robin Patroni Monitor events in the robin-patroni-monitor Pod.
To view the events in the Patroni Pod, run the following command:
# kubectl logs --follow -n robinio <patroni Pod name>
Example
[robinds@cscale-82-61 ~]# kubectl logs --follow -n robinio robin-patroni-monitor-748b56476-7k5z7
{"zoneid": "1720063271", "type_id": 21002, "object_id": "robin-patroni-2", "timestamp": 1720655282.398766, "payload": {"description": "robin-patroni-2: State is 'stopped'"}, "level": "WARN"}
{"zoneid": "1720063271", "type_id": 21004, "object_id": "robin-patroni-2", "timestamp": 1720655297.6557193, "payload": {"description": "robin-patroni-2: State is 'running'"}, "level": "INFO"}
{"zoneid": "1720063271", "type_id": 21001, "object_id": "robin-patroni-1", "timestamp": 1720655521.8451483, "payload": {"description": "robin-patroni-1: Promoted to Leader (master)"}, "level": "INFO"}
{"zoneid": "1720063271", "type_id": 21002, "object_id": "robin-patroni-0", "timestamp": 1720655577.8727887, "payload": {"description": "robin-patroni-0: State is 'stopped'"}, "level": "WARN"}
{"zoneid": "1720063271", "type_id": 21003, "object_id": "robin-patroni-0", "timestamp": 1720655638.9599402, "payload": {"description": "robin-patroni-0: State is 'stopped'"}, "level": "ERROR"}
{"zoneid": "1720063271", "type_id": 21004, "object_id": "robin-patroni-0", "timestamp": 1720655664.435924, "payload": {"description": "robin-patroni-0: State is 'running'"}, "level": "INFO"}
19.3.3. Patroni Events¶
The Robin Patroni Monitor feature generates the following Event types to the robin-patroni-monitor Pod logs if there are any change in status the Patroni replicas:
You can view the events by running the robin event-type list command. For more information, see Listing event types.
Event type |
Level |
Description |
|---|---|---|
EVENT_PATRONI_LEADER_CHANGE |
INFO |
The event is generated when there is a change in Leader role in the Patroni cluster. |
EVENT_PATRONI_INSTANCE_NOT_READY |
WARN |
The event is generated when any of the replicas in the Paroni cluster are in the NotReady status. |
EVENT_PATRONI_INSTANCE_FAILED |
ERROR |
The event is generated when any of the Patroni replicas are in the Failed status. |
EVENT_PATRONI_INSTANCE_READY |
INFO |
The event is generated when any of the Patroni replicas moved to the Ready status. |