1. Rakuten Cloud-Native Platform Overview¶
Rakuten Cloud-Native Platform (Robin CNP) is a Kubernetes-based platform that automates the deployment, scaling and lifecycle management of Data and Network intensive applications. Robin ships pure open-source Kubernetes in a batteries included, but replaceable, packaging mode. Robin supports the open-source Kubernetes that is shipped with the product and provides automated installation, frequent upgrades, and monitoring. However, because Robin platform capabilities don’t require any changes to open-source Kubernetes, one may choose to replace the built-in open-source Kubernetes with their own distribution of CNCF-certified Kubernetes (including on-premises or cloud-vendor distributions).
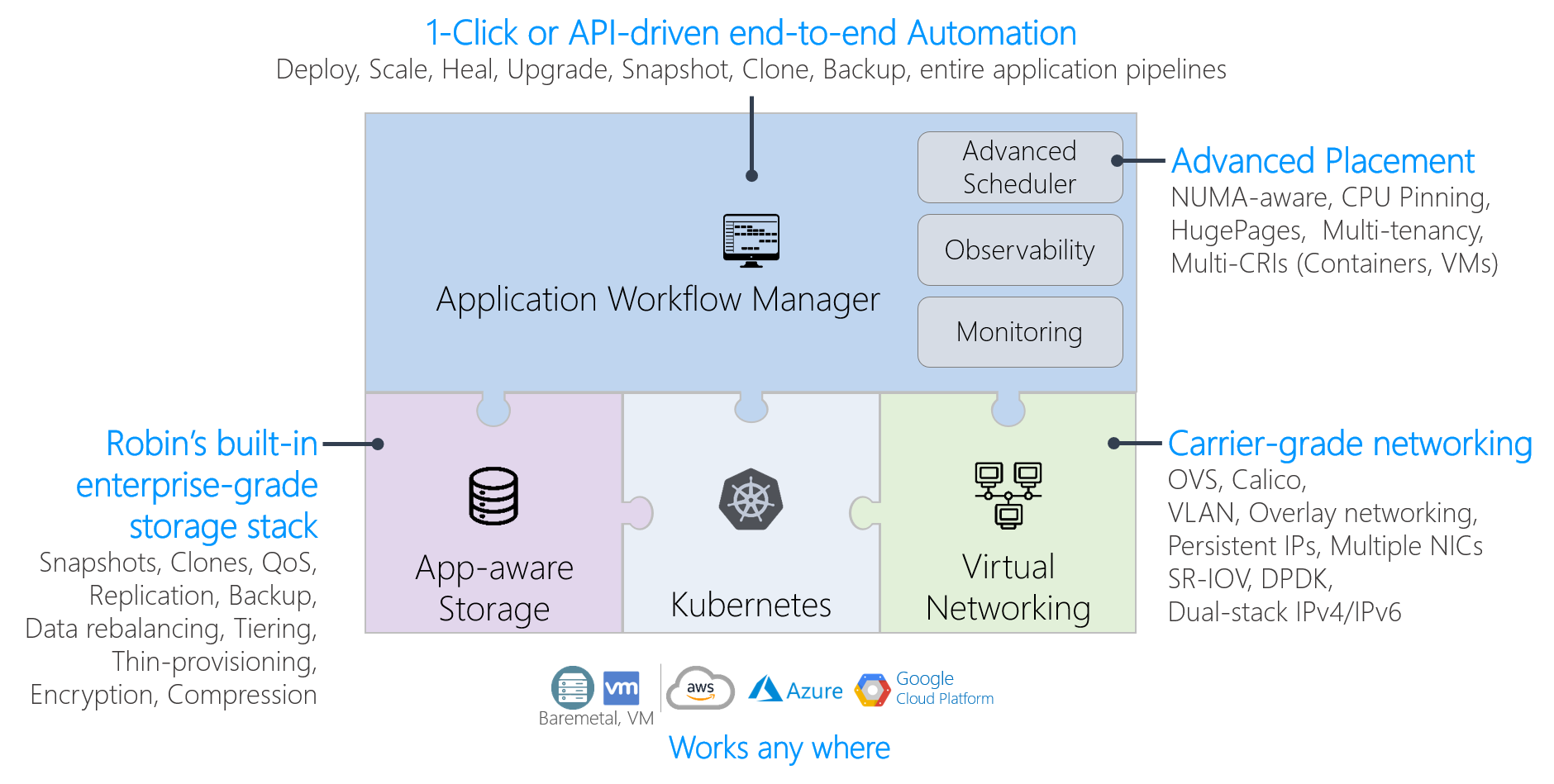
1.1. Summary of Robin Capabilities and Differentiation¶
Cluster Operations, Monitoring and Observability
Fully automated (unattended) installation on-premises (Baremetal, VMs) and Cloud (AWS, Azure, GCP, IBM)
Run Containers and VM on Kubernetes and manage their lifecycle using one common interface
Built-in highly-efficient monitoring and metrics collection of hardware components, pods and applications
Built-in holistic observability (compute, network and storage) using Robin’s sherlock tooling
Rich Multi-tenancy and Role Based Access Control (RBAC) capabilities
Robin MDCAP to manage 100s of thousands of 5G and Edge clusters (from baremetal, OS, K8S to App)
Advanced Scheduling and Placement Policies
Most advanced support for multi-service affinity, anti-affinity, data locality, infra-aware placement policies
Most advanced support for NUMA-aware scheduling policies for complex Data and Network apps
Built-in application-aware QoS policies
Most advanced support for Node, Rack, Lab and Datacenter placement policies
Capabilities for Data-Intensive Applications
Built-in Industry’s first and only application and infrastructure aware Storage and Data Management stack
Simplifies storage and data management by presenting a clean and operational simple user experience
High-performance (consistently beats competition + baremetal performance across many workloads)
Highly-scalable (multiple petabytes under management in production deployments at customer sites)
Built-in data resiliency through synchronous replication and automatic re-sync on failures
Snapshots and Backups are application-centric (captures application data, configuration and metadata)
Built-in encryption and compression
Rapid failover of storage volumes to restore access to data even under network partitions (8x faster)
Built-in support for most databases and big data stores, including MongoDB, Cassandra, ScyllaDB, Postgres, MySQL, Oracle, Oracle RAC, SAP HANA, Elastic, Splunk, Cloudera, Hortonworks, and many more
Capabilities for Network-intensive Applications
Persistent IP addresses on Pod failover (useful for deploying complex network functions on Kubernetes)
Built-in support for multiple CNI plugins simultaneously (Calico, OVS, SR-IOV, …)
Multiple NICs per Pod with advanced VLAN support
Most advanced support for SR-IOV (discovery, allocation and management) for both CNFs and VNFs
Simplified connectivity between apps on Kubernetes and apps outside (without going through NAT, LB, etc)
Support all capabilities to deploy and manage RAN (Radio Access Network) both CU and DU components
Application Deployment and Lifecycle Management
Built-in support to Snapshot, Clone, Backup or Migrate any Helm or Operator based application
Using Robin SuperOperator run any complex app with minimal K8S, Storage or Networking knowledge
1-Click clone entire applications (data + configuration + metadata) from production to test/dev
1-Click or policy-based automatic resource scaling (vertical) and service scaling (horizontal)
1-Click application stop, restart, relocate (capabilities missing in vanilla Kubernetes or competition)
1-Click application snapshot, time travel, backup & restore (for Helm-based and Robin Bundle-based apps)
1-Click application portability across multiple clusters or clouds
1-Click application upgrades (DAG based automation + validate on clone before upgrading production app)
Unspported Feature - Dedupliction Rakuten Cloud-Native Platform does not perform software-level deduplication. This is a thoughtful architectural decision, not a missing feature. Software-defined deduplication at the storage layer introduces latency, CPU overhead, and failure complexity that directly conflicts with the performance and reliability requirements of cloud-native workloads — whether those workloads run at the edge, in a private data center, or across a hybrid environment. Every major cloud-native SDS competitor has reached the same conclusion, which explicitly relies on underlying hardware for deduplication rather than implementing it in their own software layer, and for these reasons, CNP does not support deduplication, and there is no roadmap.
1.2. How to read this documentation?¶
This document covers several topics that lets you take advantage of all the features of the Robin platform so that you can maxmize the benefits from using the industry’s leading storage and data management offering for stateful applications on Kubernetes. Each feature described in this documentation has at least one of the following following mediums for usage described:
CLI
Every command that is described within the CLI tab corresponds to one that is readily available via the Robin client. These commands
provide an accessible entrypoint for any level of user to utilize the rich feature set of the platform. In addition it provides an interactive
and intuitive way for users to attain information about their cluster, perform lifecycle management operations on applications, and monitor
activity on the Robin cluster. The client is installed on the base host as part of the Robin installation process allowing for immediate
readiness and usability. Steps on how to download and setup a remote version of the Robin client are described here.
Each available section contains a brief description of the intended result of the issuing the specified command alongside an explanation of the associated parameters (both mandatory and optional). Moreover an example of each command and the resulting output is displayed in order to aid user understanding.
API
Every command that is available on the aforementioned Robin client has a corresponding API equivalent. This is because the Robin client essentially makes REST API calls to the Robin server in order to achieve the desired functionality. These API definitions are useful when building automation scripts that involve no human interaction and/or enabling northbound systems to integrate with the platform seamlessly.
Each available section documents the endpoint and corresponding port to utilize when making the API call alongside the appropriate method, mandatory URL/Data parameters, necessary headers, and expected response codes. Moreover there is an example response highlighting what is returned to the user when a succesful call is made. The IP address to utilize when making the API call depends on the configuration of the Robin cluster one is trying to contact:
If the destination Robin cluster is a non-HA setup, the IP address that should be used when issuing any API call is the IP address of the master manager node as this is where the Robin server will be hosted.
If the destination Robin cluster is a HA setup, there are two different addresses that can be used. As mentioned previously the IP address of the master manager host can be used. However given that host failovers can occur, it is recommended that the
VIPprovided during the installation process be used. In combination with the latter, if therobincp_modeconfig attribute is set one can utilize the port29465for all API calls.
Note
If the API documentation is missing for a particular command or an example of the API call being made by client is need, one can append --urlinfo to any CLI command to see the cURL request being made.